Code Reuse By Inheritance
Code Reuse By Inheritance
The other thing you can use inheritance for is to share code between multiple classes. A prime example for this is Active Record, where a concrete record class (for example a BlogPost) extends from a base class which adds the database access logic.
I personally think that the latter is one of the worst things you can do in object oriented design. Bear with me for a moment and let me try to explain why I think that.
Inheritance
To me, inheritance has two properties:
Defining an is-a relationship
Making it possible to share code between classes by extending from a common base class
The is-a relationship between classes is one thing I like to use inheritance for. So, to me, a concrete Cache - for example a MemcacheCache implementation - extending from an abstract Cache base class is a very sane thing to do. Implementing an interface means, in my opinion, adding an additional usage aspect / feature to a class, while the base class defines the type of a class. Mind: The base class, most likely, only defines abstract methods and does not provide any implementation in this case. I discussed this in more detail in a dedicated blog post, which is why I skip a detailed explanation now.
Get a Qafoo expert on-site to train your team in object oriented design and support you in developing more efficient and maintainable web software.
The other thing you can use inheritance for is to share code between multiple classes. A prime example for this is Active Record, where a concrete record class (for example a BlogPost) extends from a base class which adds the database access logic.
I personally think that the latter is one of the worst things you can do in object oriented design. Bear with me for a moment and let me try to explain why I think that.
Active Record
With Active Record, the problem is fairly obvious: The base class usually implements the storage logic, while the extending class is supposed to implement the business logic and maybe additional table query logic.
The business logic (or domain logic) is the most important part of your application – the stuff you earn your money with. You probably want to test this logic since you might be broke if it fails too hard.
Unit-testing a class which uses logic from a base class, for example accessing the database, is a lot of work. The best way is usually to mock all methods (from the parent class) which access the database and then run the tests on the mocked subject while correctly simulating the return values from your database. This is damn tedious.
Not wanting to go into too much detail here, but testing an Active Record class as-is is often even worse since tests which hit your database are usually damn slow, harder to set up and harder to keep atomic. But most importantly, unit-tests should fail for only one reason, and also testing a database access layer will likely make it a lot harder to locate the exact reason for unit test failures.
A Smaller Example
One of my preferred examples when describing this to others is a mistake in a component design I made not too many years ago. I wanted to write a little diff component, which makes it possible to evaluate the line-wise diffs in source code, but also paragraph and word-wise diffs for wiki articles and blog posts.
When writing the component, I started implementing the most common diff algorithm on top of "tokens", which should allow me to handle all the cases mentioned before. Once the algorithm worked, I derived from the class, implementing the different diff flavours:
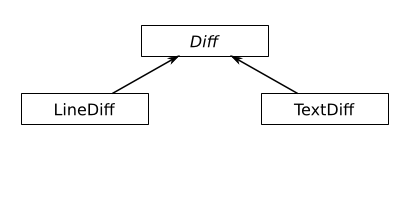
That worked fine for some time, but once the diff component was integrated into PHPUnit, Sebastian Bergmann noticed problems with large texts and we realized that there are better diff algorithms for particular large texts. The LineDiff and TextDiff classes, implementing their respective tokenizing rules, are still fine, but we wanted to replace the algorithm in the base class depending on the diff use case. This is, of course, not possible. A better class design would obviously be:
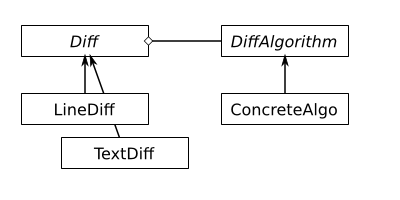
We can now replace the used diff algorithm, test it directly based on simple token streams, and every concrete Diff implementation (LineDiff, TextDiff, …) will still work with all the diff algorithm implementations you can come up with. A downside, of course, is that creating the Diff object gets slightly more complex, but this is usually handled by a Dependency Injection Container, anyway.
The Helper Method
The points where Code-Reuse-By-Inheritance still keeps creeping into my code from time to time are small helper methods. For example for complex data structures it is so easy to just define a method in the data structure which calculates some kind of hash, to apply simple transformations or to validate some values. The next thing you notice is that you will move those methods up in the extension hierarchy or copy it around (maybe slightly modified).
Why not make it a (single) public method in some Hasher, Validator or Visitor class? You might be surprised how much easier stuff gets to test and that you might even be able to re-use that code in even more places. I guess the fear of (many) classes applies here again, which I consider void. But this is another blog post.
Of course it is valid to have such helper methods during prototyping, but if you start using such code in multiple places, start testing it or start to put it into production you should refactor it to follow the mentioned concerns.
In most cases, those helper methods are also a different concern which you start mixing into your class. Even the concern seems closely related, it probably does not hurt to move it somewhere else and make it explicit.
It may happen, though, that people start to over-engineer given these constraints. But every developer walks on a very fine line between missing abstraction and over-engineering all the time, anyway. A good base for a decision could be: Will it ever make sense to somehow re-use this piece of code or may it be possible that someone wants to replace this implementation in a similar use case or during testing?
Testing Private Methods
The urge to test private or protected methods is, in my opinion, a code smell which should directly lead to refactoring.
Once you separate your concerns and move code you share by inheritance into its own classes, every non-trivial code will be contained in public methods which are easy to test. And more importantly: easier to understand.
Depth Of Inheritance Tree (DIT)
Then there is the "Depth of Inheritance Tree" (DIT) metric with a common boundary value of 5, while the counting even stops at component borders. To me, the maximum value for this metric should be considered 2. Except for some struct classes / value objects, there is, in my opinion, no reason for more then one level of extension of a class. If you use inheritance just for defining the _type_ of classes, you will never extend more than once. If you are tempted to do that, use aggregation instead and you are probably fine in 99% of all cases.
If you have valid use cases for an inheritance hierarchy greater than two, please share those with me.
Summary
To me, by now, Code-Reuse-By-Inheritance is a clear code smell. Every time I am tempted to do this or find this in existing code, I will refactor out the code into a separate class as soon as possible.