How To Synchronize a Database With ElasticSearch?
How To Synchronize a Database With ElasticSearch?
Since search engines like Apache Solr and ElasticSearch are easy to use and setup more and more applications are using them to index their content and make it searchable by the user. After all the underlying Lucene index engine provides far more powerful features then a plain MySQL full text search or similar solutions. With Apache Solr and ElasticSearch you can enhance the performance and the functionality of your website.
What we often stumble across, though, is the naiive approach of synchronizing both data storages. It boils down to:
Store data in database
Store data in search index
The problem with this approach is, as in any distributed system, that both the first and the second write will fail at some point. When the first write to the database fails usually nothing is indexed. When the second write to the search index fails you have content which exists but the user won't be able to find it in the search index.
Depending on your domain this might not be a problem. But if a price update of a product in an online shop fails you might actually loose money or at least customers will be angry about the inconsistencies on your site. There will be similar problems in other domains.
Transactions
The second idea of most developers now have is to build some kind of transaction support across both storages. We know transactions well from our Computer Science courses and relational database management systems, thus it is an intuitive decision. With a transaction wrapped around you'll get something like this:
try {
$database->store($document);
$searchIndex->index($document);
} catch (IndexException $e) {
$database->remove($document);
// Inform user that write failed
}This works, but it puts the burden of resubmitting the document and handling the failure in your application on the user. Resubmitting a complex document might or might not work in a sane way for your users. If the user edited a long and complex text and all edits are lost because the search index failed to update – your user might not be that happy.
Changes Feed
There is a better way to implement this, often used in systems where you have one primary storage and any number of secondary storages. In this scenario your primary storage defines the state of your system – it is commonly called "Source Of Truth". In this example your database knows the definitive truth since everything is first stored there. Any other system, like your search index or caches should be updated based on the state in the database.
What we want to do is passing every change in the database on to the search index. A changes feed can do this. Some databases like CouchDB offer this out of the box for every document, but how can this done with a relational database management system like MySQL? And how can the data be passed on safely to the search index? The process behind this can be illustrated by this simplified sequence diagram:
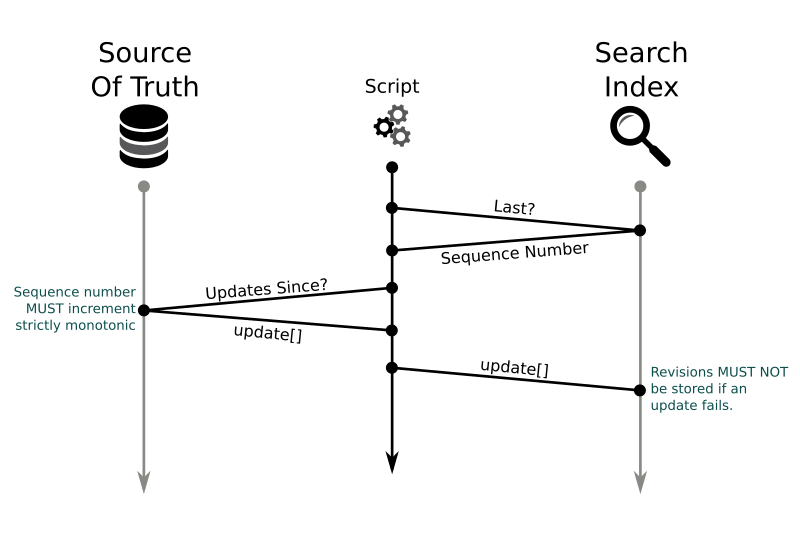
The idea behind this is that we start asking the target system (search index) what document it already knows. For this we need some kind of sequence number or revision – which MUST be sortable & strictly monotonic to make sure that we do not loose any updates. With the last sequence number returned from the target system we can now load all or just a batch of changes from our database. These changes are then pushed to the search index. This sounds simple, right? But there are two questions remaining:
How to I get MySQL to produce correct sequence numbers?
How can I store the last sequence number in the search index?
Generating Correct Sequence Numbers
This is the hardest part with the described architectural pattern and a little bit harder to get right then one would assume in the first place. Every sequence number MUST be bigger then the last sequence number otherwise changes can be lost.
The easiest way to implement this is an additional table with the following schema:
CREATE TABLE changes (
sequence_number INT NOT NULL AUTO_INCREMENT,
document_id INT NOT NULL,
PRIMARY KEY (sequence_number)
);The document_id would reference a data set in another table – if you want you can even define a foreign key relation with the data indexed in the search index. Defining the sequence_number number as AUTO_INCREMENT ensures that MySQL takes care of incrementing the sequence number.
With every change to a document we now also append a row to the changes table. Do this inside one transaction. Afterwards we can just query the changes like:
SELECT
sequence_number, document.*
FROM changes
JOIN -- … --
WHERE sequence_number > :since
ORDER BY sequence_number ASC
LIMIT 0, 100;This would request the next 100 changes and join them with the actual data.
This table will grow fast you say? You're right.
But this can be optimized. The only thing we must keep in this table is the latest sequence number of each document_id so that we can run a clean import in the correct order. If there are dependencies between your documents this can get a little more complex but can still be solved.
Unnecessary at first, but at some point you might also have to handle the case where the sequence_number overflows.
Storing The Sequence Number
The sequence number must not be increased in the search index if no document was stored. Otherwise we would loose the document since the next request for new documents to the database will use the already increased sequence number.
Since systems like ElasticSearch do not support transaction we should store the sequence number associated with the update right in the document. Using a MAX query and an index on the sequence number field we can still fetch the last sequence number from the search index.
Another option would be to store the last sequence number in a special document or somewhere else like the file system. If ElasticSearch now loses some or all documents we will not be aware of it and some documents will again be missing from the search index. Solutions like ElasticSearch tend to only persist their in memory data every few seconds and if the node crashes in the mean time they will loose some data. The described pattern ensures the index is brought up to date once the node recovers. Even with a complete data loss the architectural pattern described here will automatically ensure the entire index is rebuilt correctly.
Conclusion
The architectural pattern discussed in this blog post is nothing we invented. It is actually used by replication mechanisms of databases or other storage systems. We just showed you an adapted version for the concrete use case of synchronizing contents between a database and ElasticSearch.
The shown pattern is stable and resilient against failures. If ElasticSearch is not available while storing the data it will catch up later. Even longer down times or complete node failures will be automatically resolved. The mechanism is also called eventual consistency because of this.
The problem with this approach is that you'll need an extra script or cron job to synchronize both systems. The search index will also always lag slightly behind the database, depending on how often the script is run.
We generally advise to use this pattern to keep multiple system in sync when there is one source of truth. The pattern does not work when data is written to multiple different nodes.